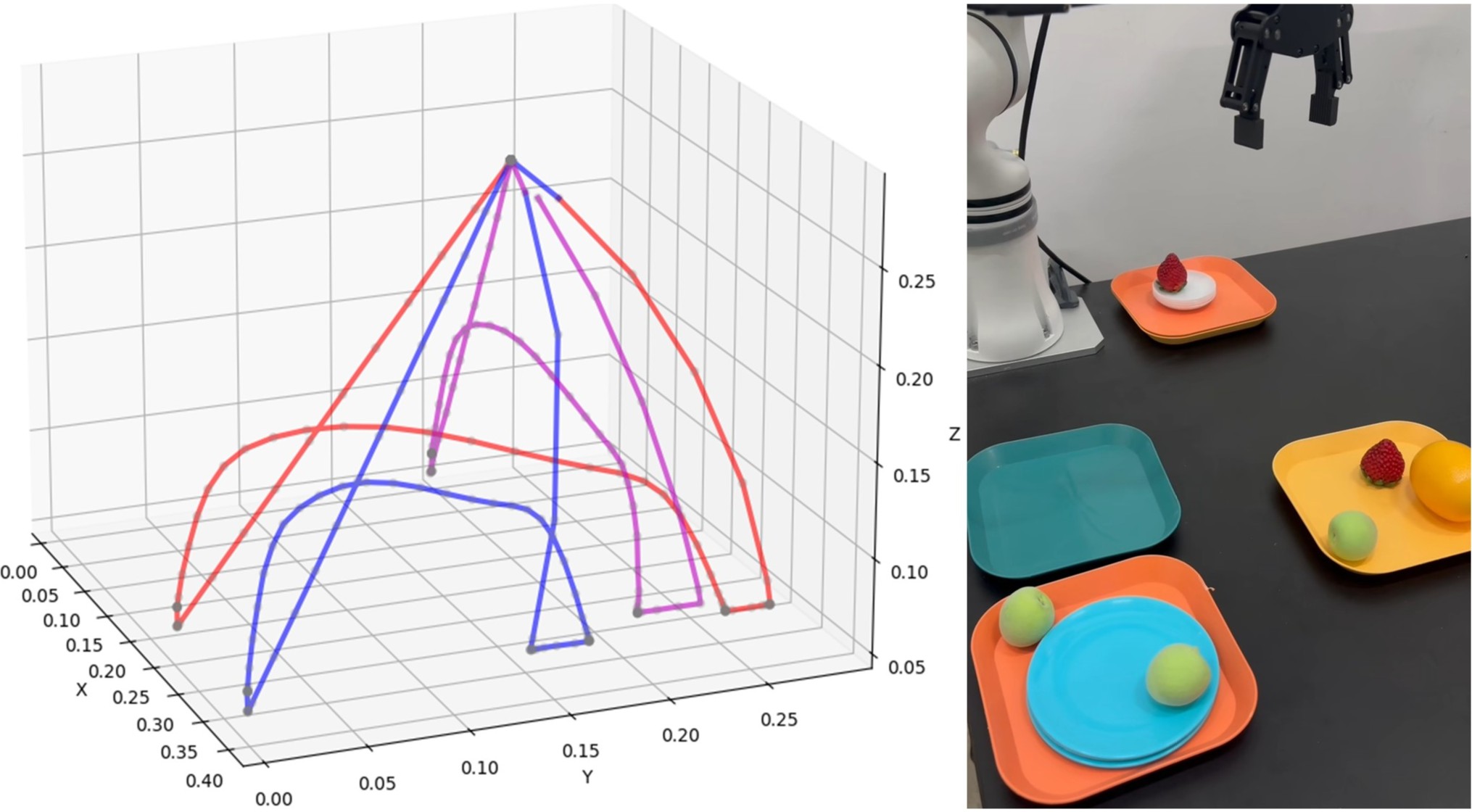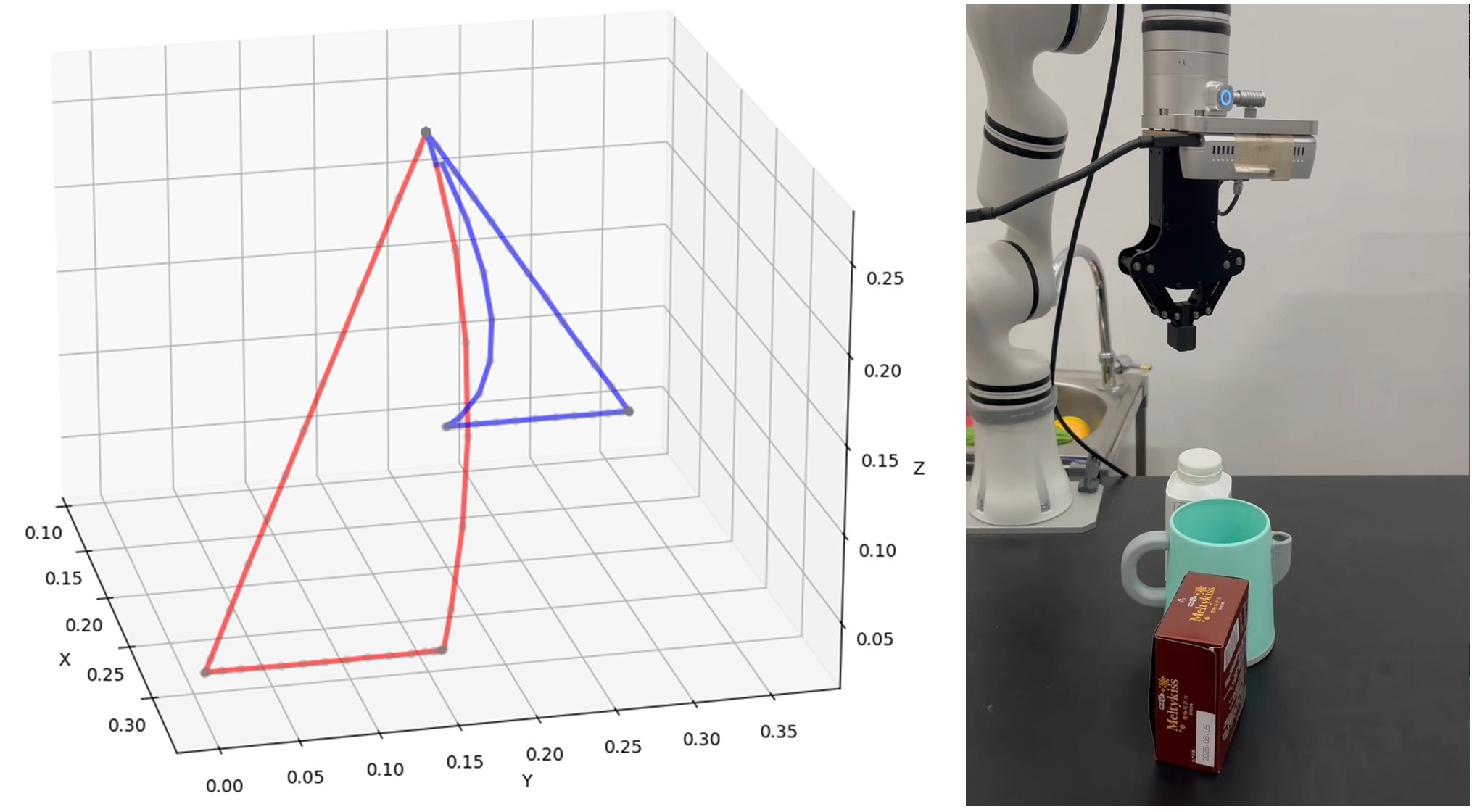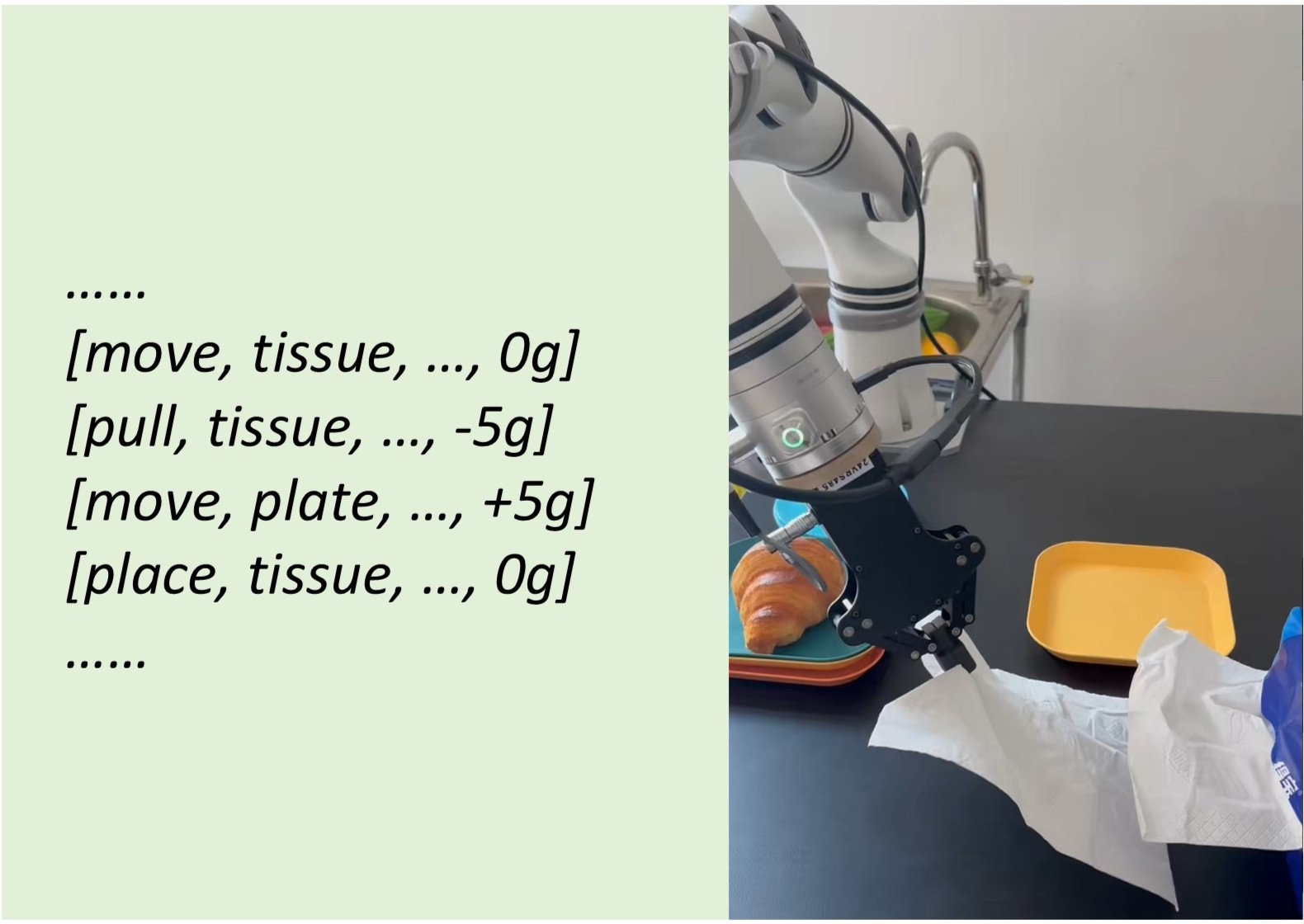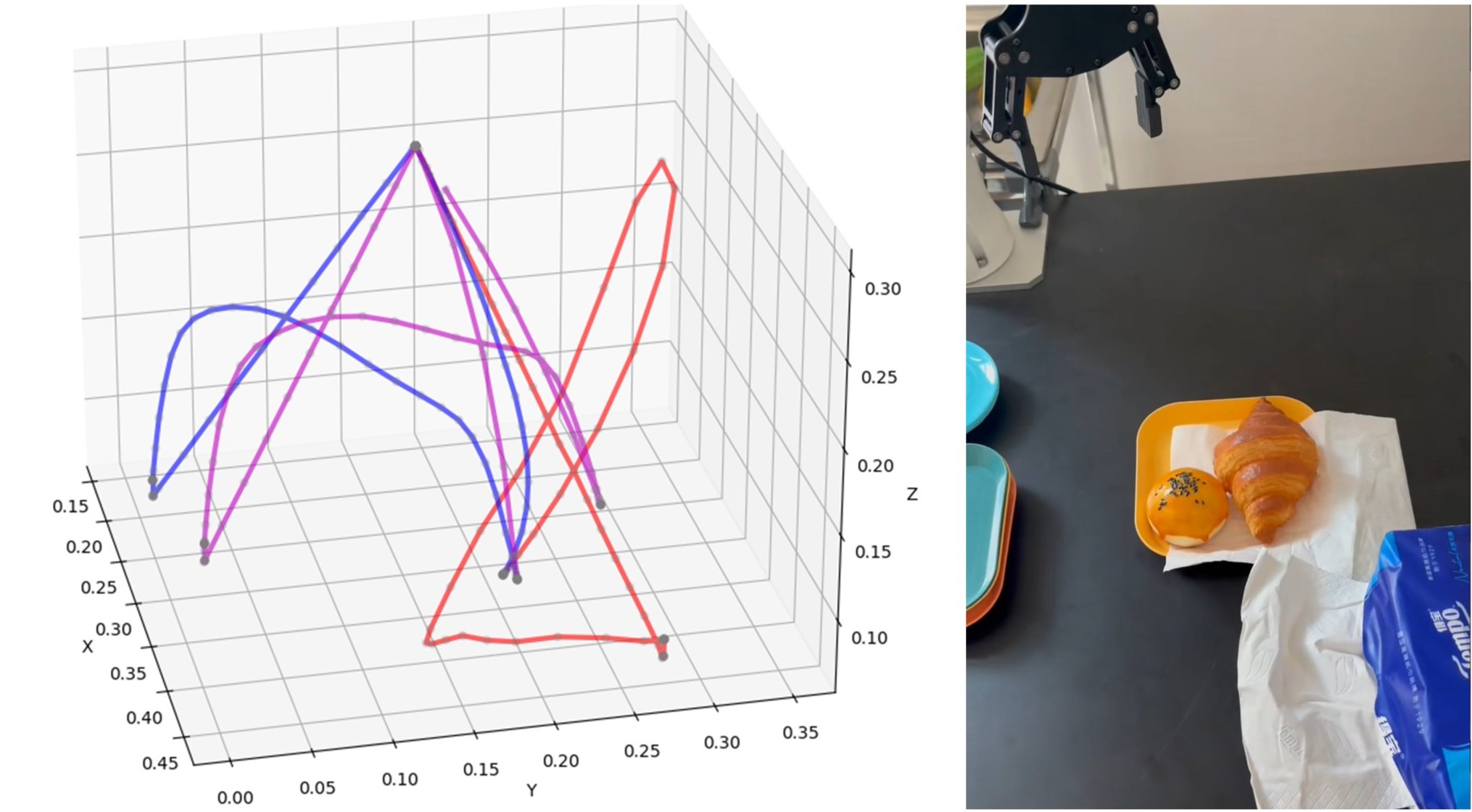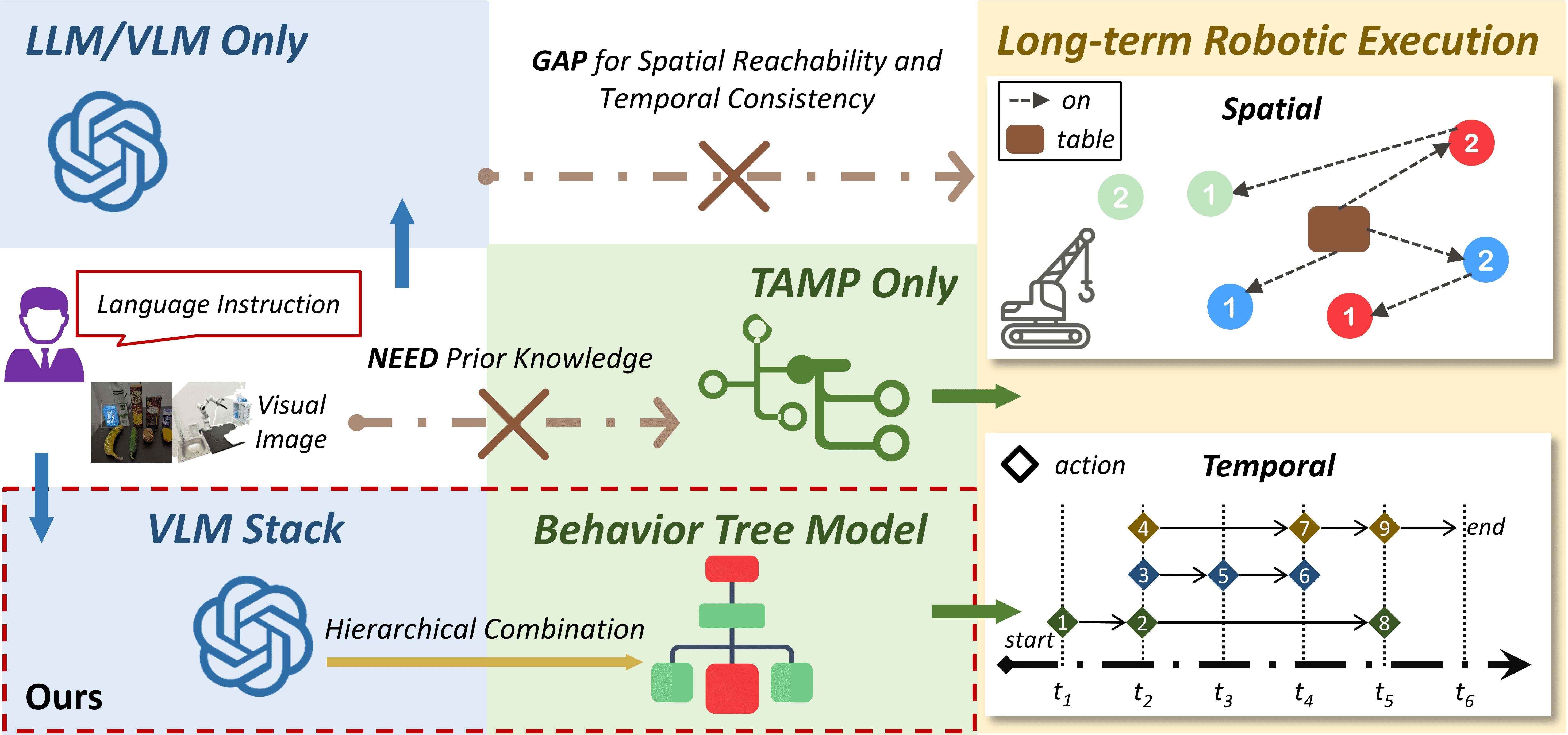
Main Contribution
We propose a hierarchical multimodal planning framework for long-term robotic manipulation ![]() that combines the strengths and overcomes the limitations of LLMs/VLMs and traditional task and motion planning (TAMP) methods.
The main contributions of our work are summarized as follows:
that combines the strengths and overcomes the limitations of LLMs/VLMs and traditional task and motion planning (TAMP) methods.
The main contributions of our work are summarized as follows: